
On Automated Self-Reflection & Search
It feels like I can make myself wiser just by thinking. Can a computer?

This short essay explores how I, a human, improve my thinking without reference to the real world, and how future AIs might be able to do the same thing. It was originally written on a deadline for the AI Impacts essay competition.
________________
Human Self-Reflection & Search
It feels like I can make myself wiser just by thinking.
That is, I seem to be able to make some improvements to my own thinking without doing any real world experiments or gathering any real world data beyond what I already have.
How could this be true?
I think it comes down to doing a sort of search, generation, and consistency checking inside my head. I guess you could call it ‘search and update’.
Suppose I have some fuzzy world model. By thinking, I can probe parts of my world model and try to find inconsistencies. For example, I might think about car engines, diving deeper and deeper into specifics until I notice something odd:
“How does a car engine work? Fuel and air mixes in a tube, where it gets compressed by a piston. Then a spark is made which ignites the fuel and air, creating heat which expands the gas and pushes the piston back downward. The piston is attached to a shaft which turns a wheel...”
“Wait, how does the piston moving linearly make the shaft rotate?”
“Hmmmmmm. Okay, I’m picturing a handle coming off the shaft, with a pivoting attachment at its end like a bike pedal. The back of the piston would also need a pivoting bit, and then you could have a rod going between the two pivoting pieces. One side rotates with the shaft and the other side goes linearly with the piston... this means that the power applied to the shaft from the piston varies with the angle between the rod and the piston, as well as with the rod and the handle!”
That was a real example of me working something out about car engines that I didn’t know before. I have a world model of physics and I have a high level understanding of engines, so I can search for reasonable “completions” that bridge these different parts of my world model.
To break down the basic structure here.
Have a fuzzy, incomplete world model.
Search through the model for inconsistencies or gaps.
Search for hypotheses that fill in these gaps or resolve these inconsistencies.
Discard inconsistent hypotheses, and add consistent ones back into the world model.
Is that me becoming more wise? I think so! Obviously the definition of ‘wise’ is up for debate, but a big part of it is clearly about being consistent-under-self-reflection, even if it’s not the only thing that makes something wise.
Now suppose that instead of searching for problems with an existing world model, I was searching for plans that moved the world into a desired state (that is, some way of achieving my goals). It’s the same process, except the hypotheses are filling in gaps between an initial state and target state, rather than resolving inconsistencies between two parts of the same model.
This is also true for generating new ideas, except the “incomplete” part of the world model is something that nobody has ever bridged before. A trivial example of this is to imagine that nobody had ever turned linear motion into rotation before by using the method I sketched out above. Since the process didn’t rely on knowing this method beforehand, it could have been the first time that idea was invented.
I want to be clear I’m not promoting this way of thinking explicitly. I’m suggesting that people already do this -- at least I do -- and that it’s extremely powerful.
Automated Self-Reflection & Search
AI today doesn’t seem to do this, at least not outside of a few cases where it is deliberately built in, like Stockfish.
But modern LLMs do have a lot of the prerequisites in place to do some form of search and update. They know far more than I do. They can store more information in working memory. They can generate ideas faster, even if those ideas are usually bad. They can even examine their own world model and suggest corrections, but these are only held in working memory, as represented by the current context.
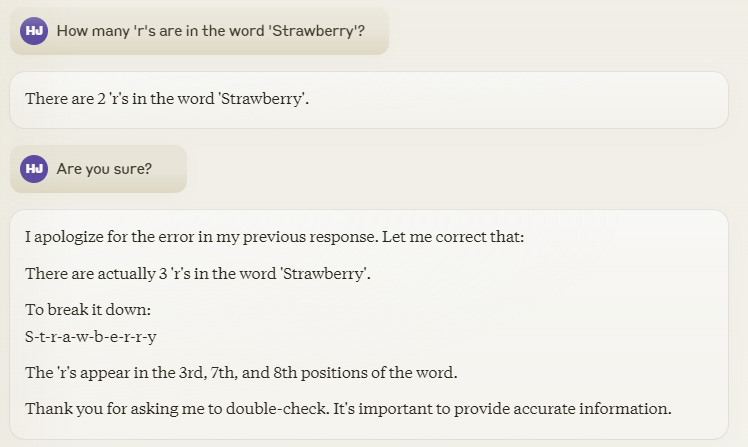
Claude Sonnet 3.5 can notice when it is wrong.
So, how could this idea actually be used with modern LLMs?
One idea is to just prompt the model well, like the example above. You can imagine a loop of “Can you find any inconsistencies with your previous response?” producing a better output. This is already a common method of improving model outputs.
Another idea is to let the model curate training data. Have the model mark the data with some score representing its confidence that it is high quality. Then you can remove low quality data from the training set or increase the salience of high quality data somehow when doing further training or fine-tuning.
But can we go further? I wonder if there’s any sensible way to give a model write access to its own parameters? Theoretically, it could use this write access to self-improve.
A naive version of this (which wouldn’t work!) is to fork the residual stream at various points, process those outputs more, and then directly add the results of that back onto either the network’s parameters or its earlier stream in a sequential loop. This is kind of like taking the model’s output and plugging it back into the input, but more permanent, and less lossy. (There’s no good way to train a model like this right now, this sketch is just to show a concept).
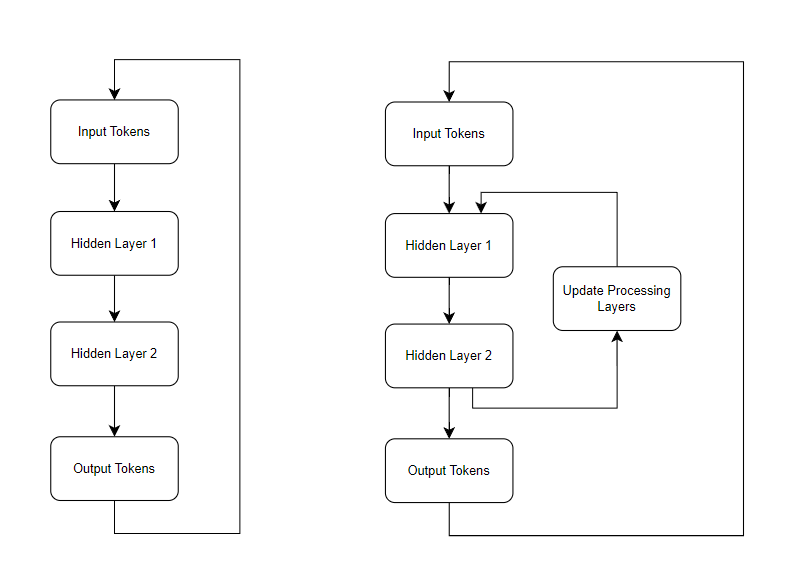
Left: A simplified model where we append the output back onto the input at each timestep.
Right: A simplified model where we do the same for intermediate points.
This implementation is dumb, but as far as I can tell it should be theoretically possible for an AI to “know” which of its own weights need to be updated.
The motivation here is that beyond a certain capability level, the model itself should have a better understanding of what caused it to get some reward than the base optimisation function does. Is there a way of using this information efficiently? This sort of self-improvement is qualitatively different to a model which figures out better ways of building other AI models (such as designing better architectures) because it’s focused entirely on updating its own, existing parameters.
Another more straightforward version of this is to let the model tune some of its own feature vectors (as determined by some mechanistic interpretability work). Straight up have the model output instructions to increase or decrease its own features in a loop. What happens? Can it find a better state than the initial one? This hits obvious problems as well (like runaway feedback loops), but it demonstrates an idea in the same class -- letting the model adjust its own parameters somehow.
What does it mean for alignment?
If a model is intelligently updating its own parameters directly, this might be a good place for alignment interventions because the process might be more transparent than traditional backpropagation. For example, suppose a model could explain what it is doing in the way a person can -- “I have noticed my model of X and Y has a contradiction, and on reflection it seems like Y is wrong, so I am updating my view on Y”. This could help, even if the actual update is an opaque set of millions of variables.
It also might make it easier to directly apply changes to the model -- “Become more trustworthy”, with the model itself using its understanding of both what trustworthiness is and how its internals are represented in order to make this change intelligently.
Of course, the trouble remains in how to actually build a self-updating model, but I think this is underdiscussed, and I will continue reading and thinking in this direction.
What does it mean for capabilities?
We already know that better quality data gets much better results when training, and we know that humans are much more data efficient than current LLMs, so it wouldn’t be unreasonable to think that a method like this could improve AI training efficiency.
There’s no reason to think human-level would be the limit here, either. I am limited in my ability to do the reflection process by the speed of my thoughts and by my extremely small working memory, which might not be the case for an AI. Historically, search based models like DeepBlue made up for poor understanding by checking many more possibilities. There may be an analogue here.
In the case where we’re searching for actions and comparing possible world states in long term plans, rather than searching for inconsistencies in a world model, the same architecture might allow larger amounts of compute to be usefully used per action. Current LLMs are pretty limited in their ability to use more compute at runtime to get better answers, this doesn’t have to remain so.
Concluding Thoughts
I think the main takeaway here is that thinking about how to use a models own understanding of the world as part of its learning seems like it will be pretty important in the future. Much more work is needed, and I feel a bit embarrassed by the fact this essay asks lots of questions but doesn't answer them. These ideas should be treated like a ‘hey, what if?’ conversation, and may or may not lead anywhere in reality. I will continue to think.